2024
Delta-Influence: Unlearning Poisons via Influence Functions
Wenjie Li, Jiawei Li, Christian Schroeder de Witt, Ameya Prabhu, Amartya Sanyal
ATTRIB @ NeurIPS 2024
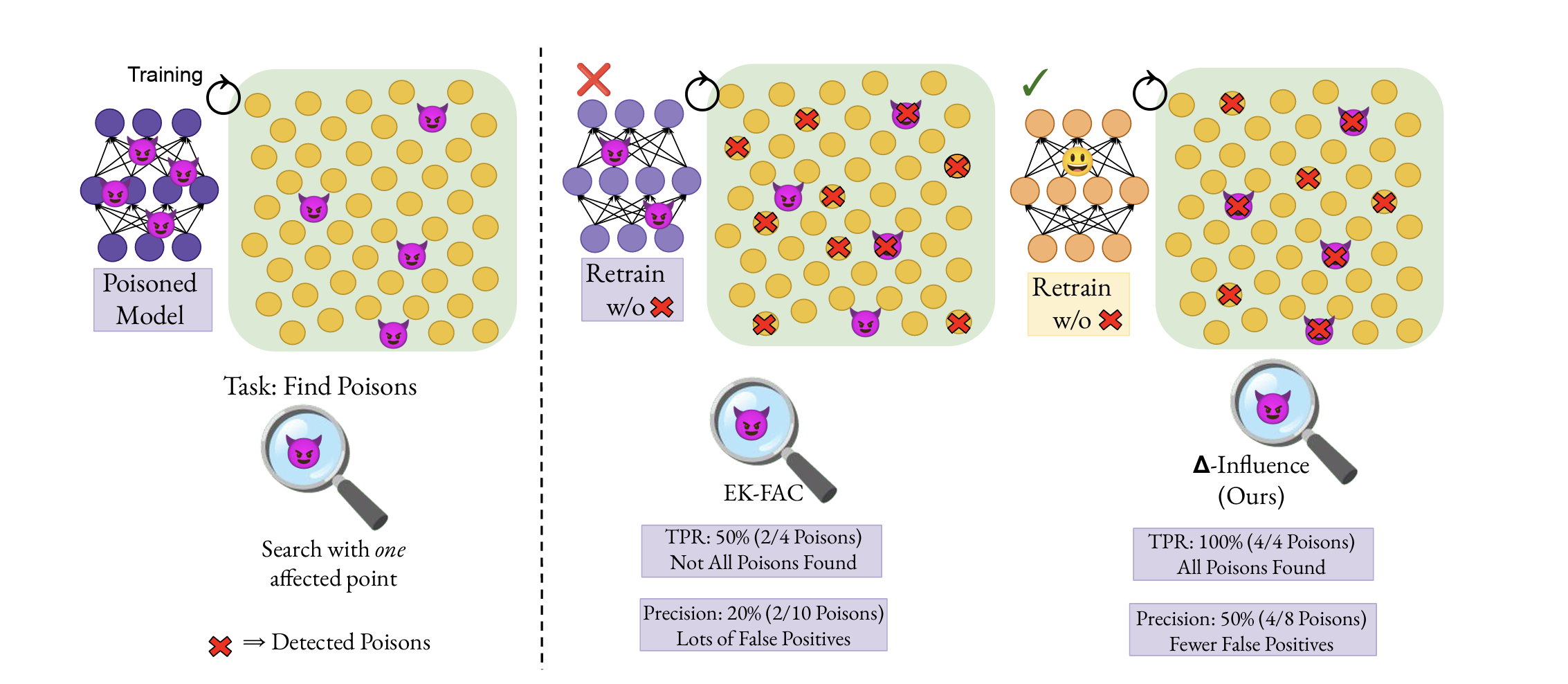
Abstract: Addressing data integrity challenges, such as unlearning the effects of data poisoning after model training, is necessary for the reliable deployment of machine learning models. State-of-the-art influence functions, such as EK-FAC, often fail to accurately attribute abnormal model behavior to the specific poisoned training data responsible for the data poisoning attack. In addition, traditional unlearning algorithms often struggle to effectively remove the influence of poisoned samples, particularly when only a few affected examples can be identified. To address these challenge, we introduce Δ-Influence, a novel approach that leverages influence functions to trace abnormal model behavior back to the responsible poisoned training data using as little as just one poisoned test example. Δ-Influence applies data transformations that sever the link between poisoned training data and compromised test points without significantly affecting clean data. This allows Δ-Influence to detect large negative shifts in influence scores following data transformations, a phenomenon we term as influence collapse, thereby accurately identifying poisoned training data. Unlearning this subset, e.g. through retraining, effectively eliminates the data poisoning. We validate our method across three vision-based poisoning attacks and three datasets, benchmarking against four detection algorithms and five unlearning strategies. We show that Δ-Influence consistently achieves the best unlearning across all settings, showing the promise of influence functions for corrective unlearning.
GameBench: Evaluating Strategic Reasoning Abilities of LLM Agents
Anthony Costarelli, Mat Allen, Roman Hauksson, Grace Sodunke, Suhas Hariharan, Carlson Cheng, Wenjie Li, Joshua Clymer, Arjun Yadav
LanGame @ NeurIPS 2024
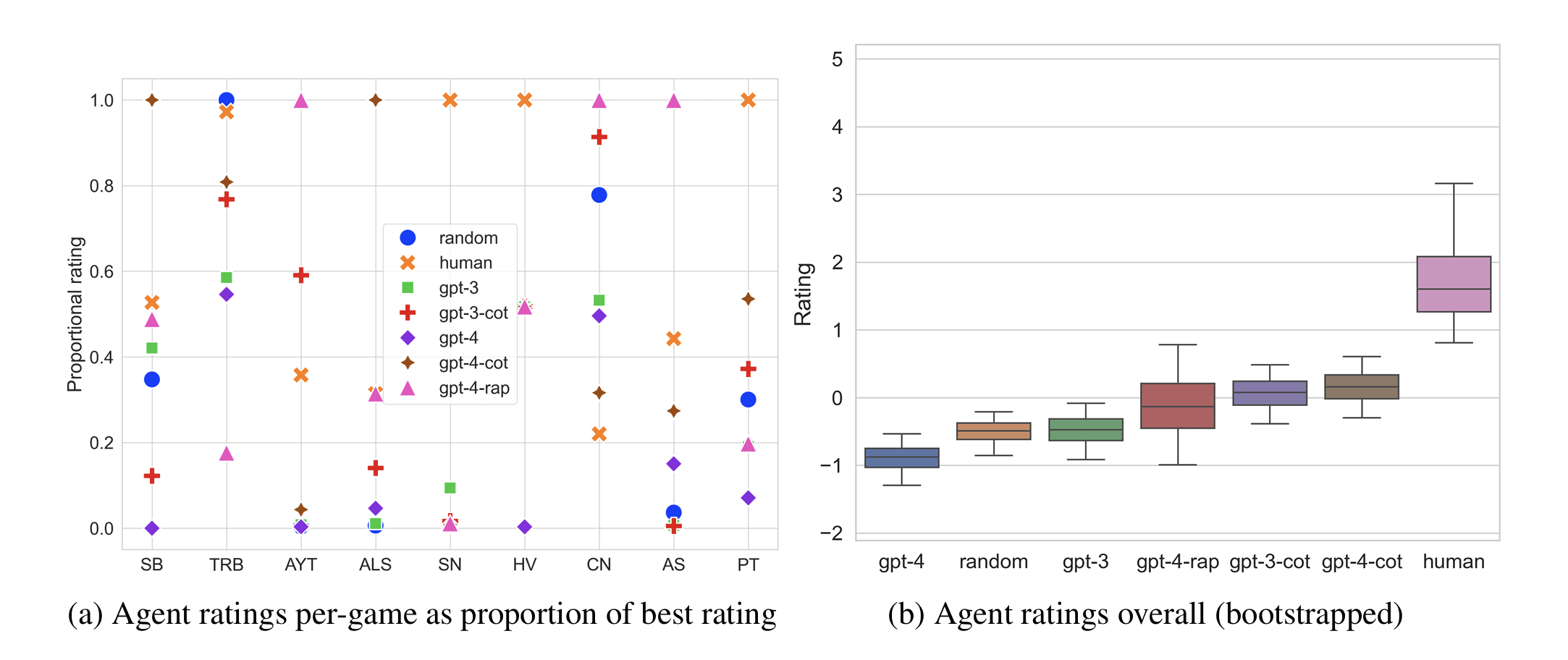
Abstract: Large language models have demonstrated remarkable few-shot performance on many natural language understanding tasks. Despite several demonstrations of using large language models in complex, strategic scenarios, there lacks a comprehensive framework for evaluating agents' performance across various types of reasoning found in games. To address this gap, we introduce GameBench, a cross-domain benchmark for evaluating strategic reasoning abilities of LLM agents. We focus on 9 different game environments, where each covers at least one axis of key reasoning skill identified in strategy games, and select games for which strategy explanations are unlikely to form a significant portion of models' pretraining corpuses. Our evaluations use GPT-3 and GPT-4 in their base form along with two scaffolding frameworks designed to enhance strategic reasoning ability: Chain-of-Thought (CoT) prompting and Reasoning Via Planning (RAP). Our results show that none of the tested models match human performance, and at worst GPT-4 performs worse than random action. CoT and RAP both improve scores but not comparable to human levels.